
CSV has been a commonly used file type to transfer large amount of tabular data from one system to another, given its simple plain text data storage and non-proprietary nature. However trouble comes when you need to break the CSV for data processing, either to create separate reports or to feed data into systems that do not support CSV. The traditional approach is to use Excel due to its wide availability and good compatibility with CSV files, but this involves a lot of time consuming manual working. Instead, we can use Power Automate to automate those data processing work and together with SharePoint to parse the CSV files automatically.
Why SharePoint?
The main reason to use SharePoint is because Power Automate has a trigger called “When a file is created in a folder”, and when this file is actually a CSV file, the content will be loaded automatically for your use. In addition, SharePoint, being a cloud based collaboration tool, can easily take in files from another system or uploaded by another user.
Dealing with CSV Dialect
Before starting to parse CSV content, we need to take care of the CSV dialect so we can handle the data correctly. CSV Dialect defines a simple format to describe the various dialects of CSV files in a language agnostic manner. It aims to deal with a reasonably large subset of the features which differ between systems, such as terminator strings, quoting rules, escape rules and so on. The three most common elements of a CSV dialect are quoting rules, delimiters and terminator string, and their actual values are defined by the CSV generating system. If you do not know the actual setting, you can open the CSV file and take a look.
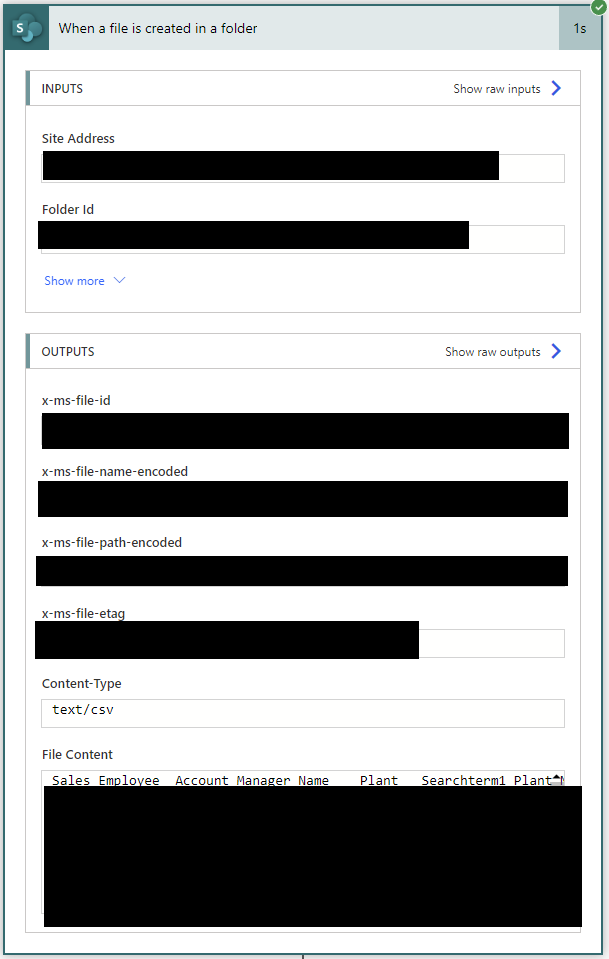
First is to remove quoting rules. The demo CSV is following an “Excel” dialect so all values are surrounded by a pair of double quotes. If your CSV does not have quoting rule, you can still add this step or safely skip this step (you may need to adjust the following steps formula accordingly). All three steps in this section are using the action called Compose under the category Data Operation
replace(triggerOutputs()?['body'], '"', '')Next is to deal with the delimiter. The demo CSV is using Tab as the delimiter so the formula below is to define delimiter as tab in the context of Power Automate processing. If your CSV is using Comma, simple replace %09 by %2C.
decodeUriComponent('%09')Lastly we need to handle terminator string, aka Line ending. It is also another headache when dealing with CSV because there are many formats. Luckily below formula can detect the terminator string used in the CSV content (after removing quoting rule) and define accordingly.
if(equals(indexof(outputs('FileContent'), decodeUriComponent('%0D%0A')), -1), if(equals(indexof(outputs('FileContent'), decodeUriComponent('%0A')), -1), decodeUriComponent('%0D'), decodeUriComponent('%0A')), decodeUriComponent('%0D%0A'))The sequence of the above 3 steps should be like below.
Split Rows and Capture Columns
After the dialect is properly handled, we can start to split the CSV rows and capture the column names since the first row of a CSV file always contains the information of the column structure.
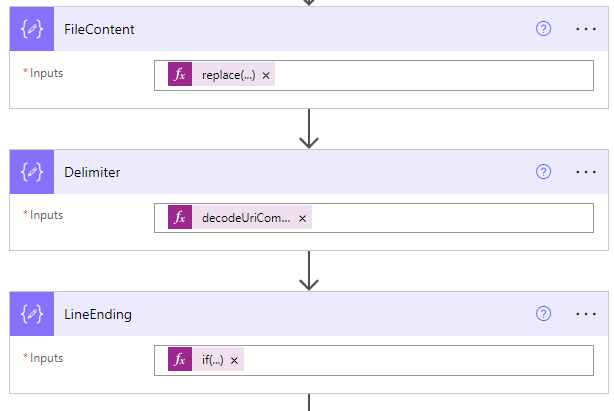
To split CSV rows is quite straight forward, just cut the CSV content with the terminator string we have defined earlier, using Compose action.
split(outputs('FileContent'), outputs('LineEnding'))To capture the columns names of the CSV file is also simple, just cut the first row of CSV content with the defined delimiter, again using Compose action.
split(outputs('SeparatedRows')[0], outputs('Delimiter'))At the end of this section, we can define an empty array to store the final product using Set Variable action, in this demo’s case, an array of JSON formatted records. You should design this based on your actual use case. The 3 steps of this section should be like:
Automate Repetitive Steps with a Loop
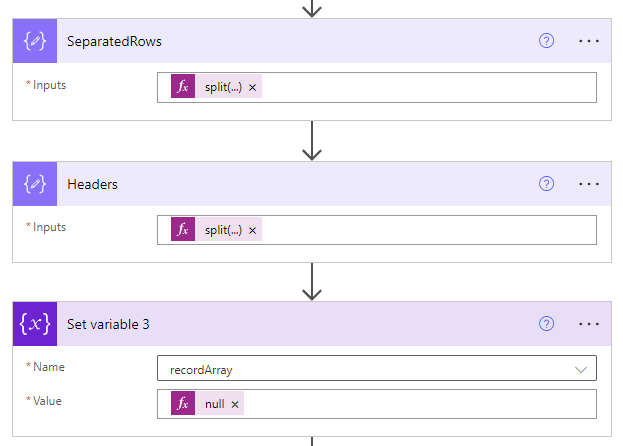
The last section is to process the CSV content row by row and put into a JSON format based on the column structure. We will use a loop to automate these repetitive steps, which include below 4 parts. The scope of this loop should cover all previously separated rows except for the first row (not containing actual data).
skip(outputs('SeparatedRows'), 1)The first part is to cut each row using delimiter and establish the one-to-one relationship with the column structure, because JSON format is based on one-to-one match of key-value pairs. We will use the Select action under the category Data Operation.
Formula for From property:
range(0, length(outputs('Headers')))Formula for Map property:
outputs('Headers')?[item()]split(items('LoopSeparatedRows'), outputs('Delimiter'))?[item()]The above three formula is a bit hard to understand but essentially they create this one-to-one relationship between the column name and its associated value for each CSV row.
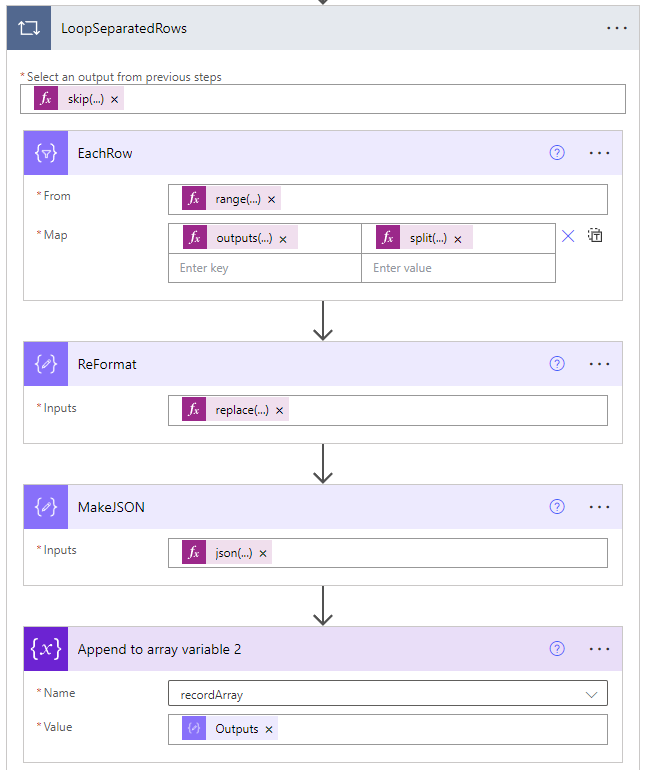
The next step is to reformat the output string from last step to be compatible with JSON format by changing [ ] and { }, using Compose action.
replace(replace(replace(replace(string(body('EachRow')), '{', ''), '}', ''), '[', '{'), ']', '}')Then we convert the string into an actual JSON object, using Compose action.
json(outputs('ReFormat'))The last step is to collect this newly created JSON object into the array for later use, using Append to Array Variable action.
outputs('MakeJSON')This section should look like below and the entire content of the original CSV file will be stored in the defined array after the loop finishes running, in this case, called recordArray.
Now you have successfully parsed the original CSV file and converted it into an array of JSON objects, with which you can search, sort, filter and do all kinds of magical stuff!